Minimally Viable Scaled Agile
For several years at MercuryWorks we wrestled with a means to tie together more than one Scrum team in the development of large software systems. Sometimes software systems are just too large for a single team with the generally-accepted “7 plus or minus 2” size to handle. Because the popular Scaled Agile frameworks tend to be more complex, I wanted to derive something just a little simpler to solve the problem.
Why Scaled Agile?
Agile in its various flavors came to the fore in the early 2000s as a reaction to classic waterfall development and, particularly with frameworks like Scrum, soon became the standard method to develop modern software. With this success came growing pains – including difficulties with multiple small fully-functional Scrum teams working on large enterprise software implementations.
Scaled Agile frameworks soon sprung up to help solve this size problem – to unify the work of multiple Scrum “feature teams” to build large enterprise systems. Most of the frameworks incorporate DevOps teams to form a cohesive process.
One of the core overarching strategies of the scaled frameworks is to align technology and business strategy at a more strategic level. By coordinating the moving pieces of large Product releases, the scaled frameworks take a larger “portfolio” view of the enterprise and value chain.
Problems With Multiple Teams and No Scaled Framework
Mercury has made a few attempts at building large software systems using Scrum but without the use of a scaled framework. The following are common problems we ran into:
- Reduced productivity
- Divergent Product visions
- Divergent architectures
- Divergent user experiences
- Conflicting cross-team coding work
Universal Elements of All Scaled Frameworks
There are several popular Scaled Agile frameworks including SAFe, LeSS and Nexus. While they all differ in their complexity and approach, all of the scaled frameworks attempt to unify software, operations and business teams as follows:

What Is SAFe and Why SAFe as a Starting Point?
SAFe is the most popular and long-lasting Scaled Agile framework. SAFe aims to provide a knowledge base of integrated principles, practices and guidance to unite multiple modern bodies of knowledge around software development. SAFe does not attempt to replace Scrum but rather it adds a set of additional roles and ceremonies around Scrum teams to unify their collaborative work.
Bodies of knowledge that SAFe embraces includes Lean, Agile, DevOps and Design Thinking. All of those are winners and is why I find SAFe to be a particularly strong base. However, I will admit that in full, SAFe is a very large methodology/undertaking and why I feel a “minimally viable” variation is called for in most cases.
The SAFe “House of Lean”
SAFe combines the core principles and tenets of both Lean and Agile to establish it’s own spin on the famous “house of Lean” established by Toyota. For those of you versed in the Toyota Production System, you will note the heavily borrowed metaphors and mappings back to JIT, Continuous Improvement and foundation of Kaizen, Teamwork, etc.

SAFe Lean-Agile Principles
Building on the “House of Lean”, SAFe’s Lean-Agile principles form the operating system of the SAFe approach and in many ways mirror the Agile Manifesto values. The following table enumerates SAFe’s Lean-Agile principles and some specific interpretations MercuryWorks applies in our minimally viable approach to scaled agile:
| Lean-Agile Principle | As applied in Minimally Viable Scaled Agile |
|---|---|
| Take an economic view | Prioritize backlog in descending order of outcome value divided by size |
| Apply systems thinking | Seek system maxima, not module maxima; pull work that results in a shipped system |
| Assume variability; preserve options | Don’t lock into long-term decisions when a Last Responsible Moment can be sought |
| Build incrementally with fast, integrated learning cycles | Tight vertical slice user stories, continuous deployment |
| Base milestones on objective evaluation of working systems | Assessment of targets are based on shipped software and not proxy measures (finished stories, lines of code, etc.) |
| Visualize and limit WIP, reduce batch sizes and manage queue lengths | Respect and monitor Scrum team capacity limits, visualize operations activities |
| Apply cadence, synchronize with cross-domain planning | Set fixed-length sprints, lock start/stop across teams, Scrum of Scrums |
| Unlock the intrinsic motivation of knowledge workers | Provide autonomy across teams, reinforce system goals, not local proxy measures |
| Decentralize decision-making | Set the mission at the system level and empower each team to determine means and make ground-level decisions |
| Organize around value | Organize teams around discrete areas of the value chain rather than all works on all |
The Agile Release Train
The Agile Release Train (ART) is the collection of feature development teams, operations team(s), business stakeholder(s) and delivery pipelines centered around a value stream. Often when people refer to the ART they are referring to the delivery pipeline of the team that results in the continuous release of software so keep that in mind when talking Scaled Agile.
SAFe also makes a nice addition of the term “Continuous Exploration” (CE) to form a triumvirate with the CI/CD acronyms that Scrum and DevOps practitioners are used to. The following diagram shows the evolution across the “train” from discovery/product management through released working software:

“Continuous Exploration” is another term for the typical Agile/product management function for roadmapping and backlog authoring
The Program Increment
SAFe introduces/borrows another nice concept called the Program Increment (PI). A PI is the timebox during which an ART delivers incremental working, tested software. Net-net a PI is a grouped number of sprints focused around specific backlog Feature(s). In other words, a PI is to an ART as a Sprint is to the Scrum Team.
Program Increment planning ties back to backlog artifacts as follows:
- User Stories are sized with the intent of fitting inside of one sprint
- Features are sized with the intent to fit inside of one PI
- Epics are sized to fit within 2-3 PIs
One of the things that I particularly like about the use of PIs is that it brings a resolution to the often-expressed Scrum team feeling of “I know we are sprinting away every two weeks but I’m not sure how and when it all adds up”. The Program Increment gives the team (and business stakeholders) a clear goal to likely-released software and how multiple stories and sprints add up to delivered business value.

Let’s Break Down The New Roles
SAFe also introduces some new roles to the Agile/Scrum picture that helps frame up the Agile Release Train operations and Program Increment planning that I think are helpful even for a minimally viable implementation. None of these are conceptually new but their specific names and duties are fairly new to those used to practicing straight Scrum:
Release Train Engineer
- Servant leader and coach; major responsibilities are to facilitate ART events and processes and assist the teams in delivering value
- RTEs communicate with stakeholders, escalate impediments, help manage risk and drive relentless improvement
- RTEs guide the ART to hit PI goals and make decisions that meet the overall mission
System Engineer
- Responsible for defining and communicating a shared technical and architectural vision
- Help ensure the system under development is fit for its intended purpose
System Team
- Specialized team that assists in building and supporting the Agile development environment, typically including the continuous delivery pipeline(s) toolchain
- May also support the integration of assets from Agile teams and assist with deployment and release
- Works against a continuous Kanban board as opposed to a bounded sprint cadence
Two New Ceremonies
At this point you may be asking yourself “so even in a minimally-implemented version of scaled Agile, how do you keep the teams from bumping into each other?”. While I will admit that Scrum calls for a number of ceremonies, scaled Agile adds two more valuable-but-lightweight ceremonies to the picture to address coordination:
Scrum of Scrums
The Release Train Engineer (RTE) facilitates a weekly Scrum of Scrums (SoS) event. The SoS helps coordinate the dependencies of the ARTs and provides visibility into progress and impediments. The RTE and one representative from each team meet to review their progress toward PI objectives and dependencies among the teams. Timeboxed for 30-60 minutes (there can be a “stay-behind” for individuals needing a deeper dive into specific topics).
PO Sync
The RTE facilitates a weekly Product Owner Sync (PO Sync) event. The purpose is to get visibility into how well the ART is progressing toward meeting its PI objectives and discuss problems or opportunities with Feature development. The event may also be used to prepare for the next PI and may include backlog refinement and prioritization ahead of the next PI planning event. Timeboxed for 30-60 minutes.
A Visualization of How the Pieces Fit Together

Map the Value Stream
Early in this post I made mention of the schools of thought that SAFe embraces and one of those was Lean. A common practice in Lean planning is the creation of a value stream diagram – this is a solid place to start in creating your ART. The following is a prototypical online shopping “job to be done” mapped from beginning to end:

Map Intended Subsystems to the Value Stream
Since we will ultimately need to assign portions of the eventual enterprise software system to individual teams within the ART, we next need to subdivide the overall system into modules/subsystems. Naturally at this point the System Engineer will need a pretty good concept of the eventual system composition so sufficient discovery and ideation will have had to occur.

Assign System Users to Subsystems/Modules
Since at its core Agile, Scrum and Lean are customer-centered models we strive to map intended end users to each subsystem/module so we can identify the stakeholders of each eventual team within the ART. With this final step we can make some clear choices on how and where to assign each team within the ART in a way that will result in the least dependencies and conflicts.
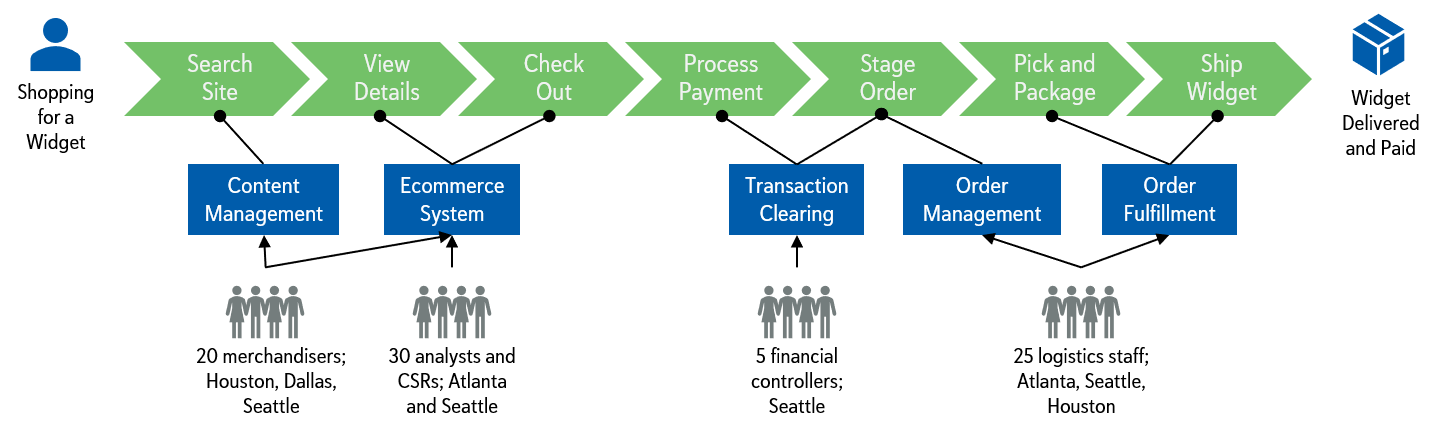
Identify Composition of the Subsystems
Once we have identified each of the subsystems and end users for each portion of the value stream we can begin to visually illustrate touchpoints across the subsystems. The following is an example block diagram for what will become the eventual enterprise system for the example online shopping solution. Note that it is worthwhile to map in third party systems – even though those will not be built by the ART (they will need to integrate into them).
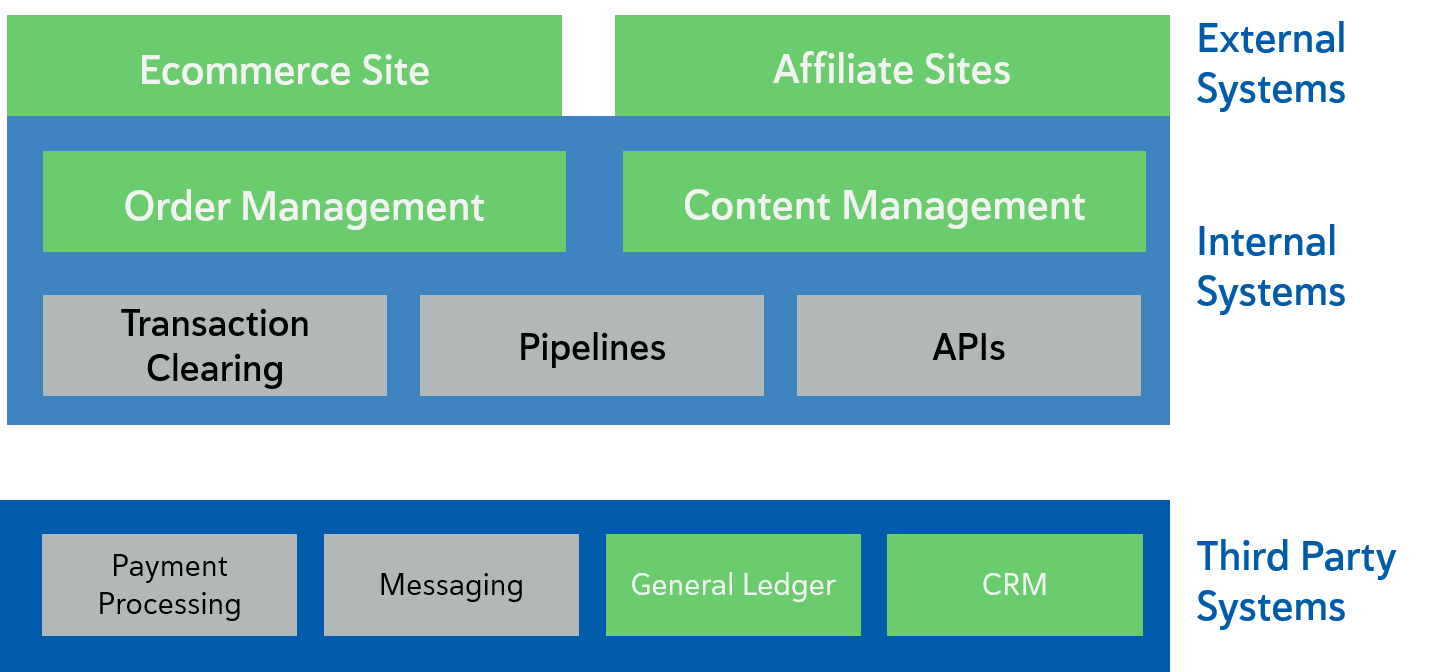
Break Down the Major Modules
A final ART planning step is to break each of the main system blocks into the pieces that are likely to be major pieces of code/data/interface. This will finally get us to the point where we can assign each team to a collection of code pieces that maps back to the value stream and thus end users.
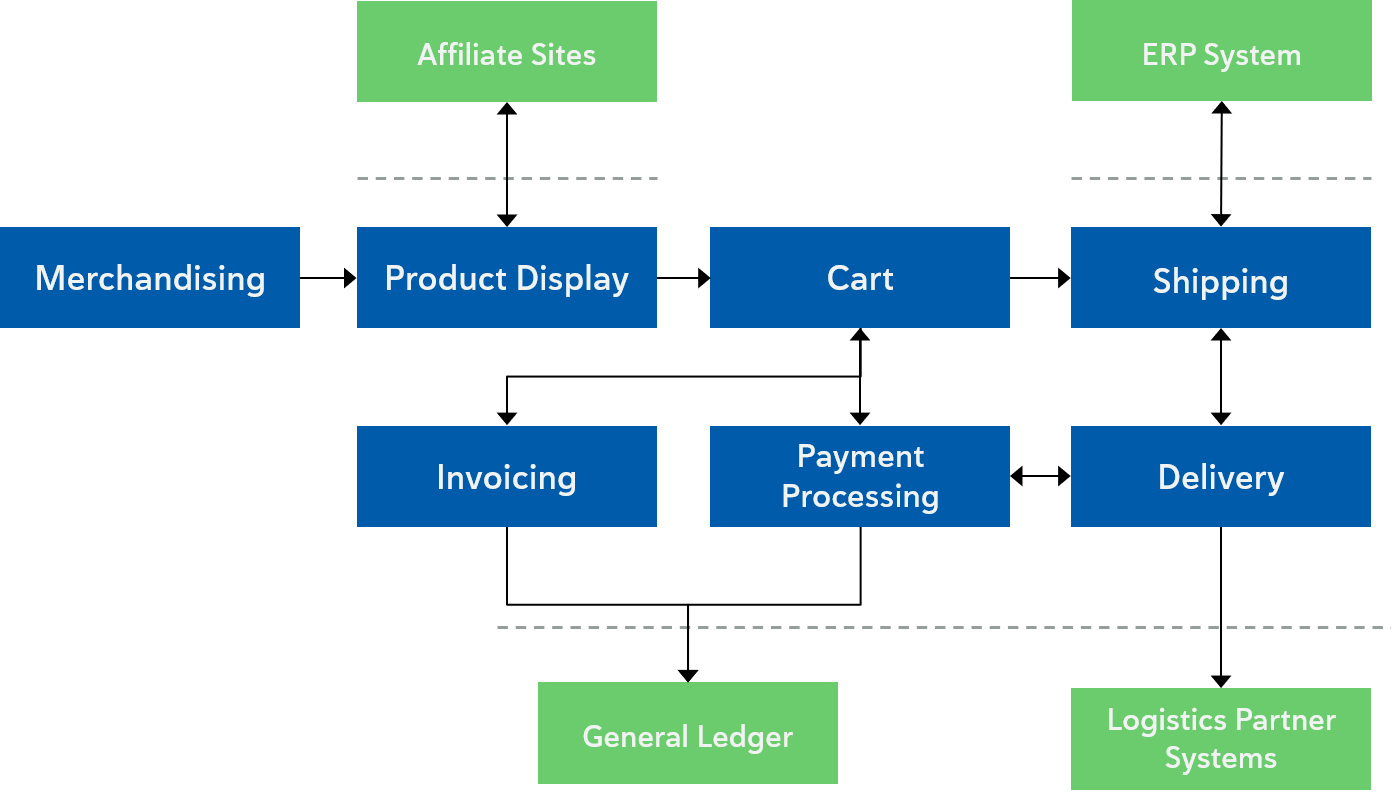
Program and Dependency Board
Now we arrive at one of the key pragmatic pieces of the scaled plan – the Program/Dependency Board. As you can see, this board maps back to the code segments/repos and is used during Program Increment planning to makes subsystem dependencies visual. In the following diagram the green and blue rectangles represent intended PI User Stories and Features while the red rectangles indicate stories/Features that have dependencies and that will require team coordination.
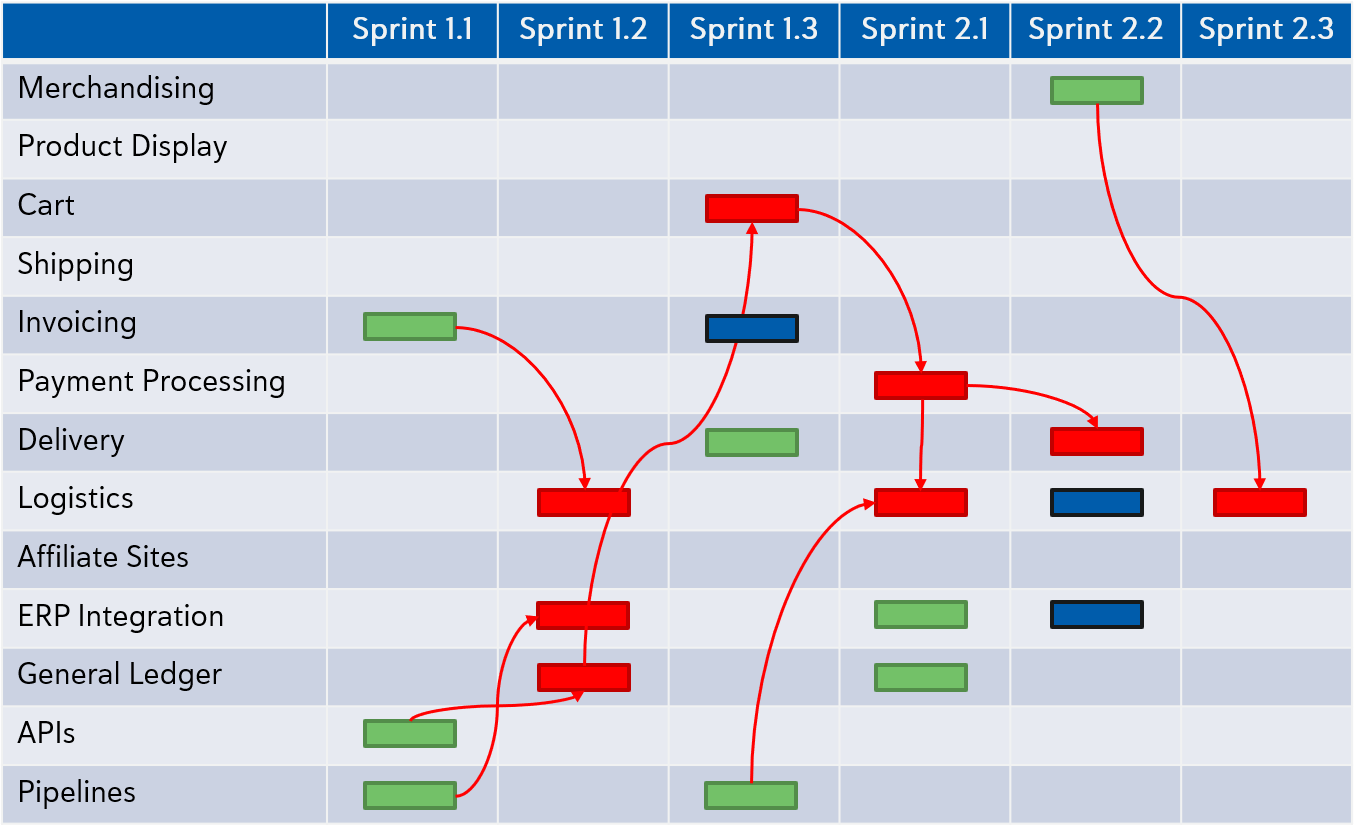
So What Does Program Increment Planning Actually Look Like?
Thus far I’ve spent a lot of coverage deciding on how to compose the ART, the system and subsystems they will be building and how to begin to get individual Scrum teams rationally assigned to actual pieces of software they will be responsible for. At this point you will have two to three Scrum teams to develop features and an enablement team to handle cloud infrastructure and pipelines. We have also established that a PI will be made up of three sprints and will ship a small number of backlog Features.
So what actually happens during PI planning? Take the following with a grain of salt and apply it to the particulars of your solution and ART but know that this is an example PI planning schedule that we have found to be effective:
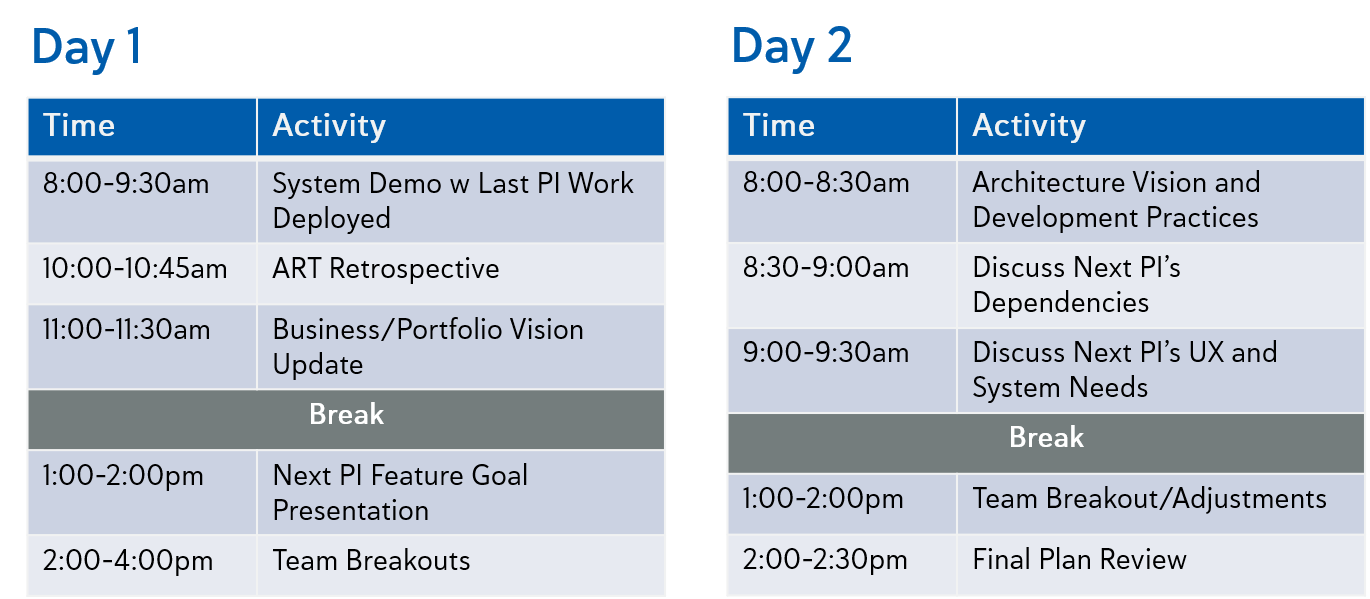
Net “Minimal” Ceremonies
Now we come to the portion of ART planning wherein we plan and schedule the needed ceremonies. The accompanying table calls out an example set of ceremonies/meetings for an ART for this example challenge (it covers both individual Scrum team and overall ART ceremonies) along with a practical frequency.
| Ceremony | Frequency | Participants |
|---|---|---|
| PI Planning | every 6 weeks | All ART members |
| Sprint Planning | every 2 weeks | Scrum team members |
| Scrum of Scrums | weekly | RTE & one rep per Scrum team |
| PO Sync | weekly | RTE & each Scrum PO |
| Sprint Retrospective | every 4 weeks | Scrum team members |
| Executive Progress Briefing | every 6 weeks | RTE & business owners |
Wrapping It All Up
At this point we have covered a lot of ground, generalized a lot of things and certainly left out a ton of details and rationale. However, I think we have covered the absolute bare minimum composition and details related to an effective start towards scaling your Agile practice. While this approach will not come close to doing justice for ARTs of more than 3-4 teams (that is what full-blown SAFe is for), I have found this to be an effective recipe here at MercuryWorks:
Unite 2+ Scrum feature teams and 1 system team into a single cohesive group called an Agile Release Train (ART)
Each Scrum team works independently in two-week sprints (we like to start Wednesday and end Tuesday)
Work in 3-sprint-long Program Increments (PI), fitting two PIs per quarter
Appoint one Release Train Engineer and one System Engineer
Each system/module build and deploy is automated and continuous
Systems/modules are released via feature flag at conclusion of each PI
SonarQube scans and cross-team peer reviews at the conclusion of each PI as a technical health and consistency mechanism
Your mileage, as they say, will surely vary but please do let me know your thoughts below! Also, to dig deeper into some of the first principles, take a look at these resources:
- Toyota “House of Lean”
- The Agile Manifesto and Scrum.org
- Scaled Agile, Inc.
- End Results: A MercuryWorks Scaled Agile Case Study
Interested in Learning More?
Fill out the form below and our team will follow up shortly.